BigData / Apache Spark
1. What is Apache spark?
Apache Spark is an open-source cluster computing framework for real-time processing. Spark provides an interface for programming entire clusters with implicit data parallelism and fault-tolerance.
2. Key features of Apache Spark.
Speed: Spark runs faster than Hadoop MapReduce for large-scale data through controlled partitioning. Spark manages data using partitions that help parallelize distributed data processing with minimal network traffic.
Real Time Computation: Spark perform computation in real-time and has less latency due to in-memory computation. Spark is designed for massive scalability that allows live production clusters with thousands of nodes and supports several computational models.
Hadoop Integration: Apache Spark provides compatibility with Hadoop. Spark is a potential replacement for the MapReduce functions of Hadoop, while Spark has the ability to run on top of an existing Hadoop cluster using YARN for resource scheduling.
Machine Learning: Spark MLlib is the machine learning component which is handy when it comes to big data processing. It eradicates the need to use multiple tools, one for processing and one for machine learning. Spark provides data engineers and data scientists with a powerful, unified engine that is both fast and easy to use.
Multiple Formats: Spark supports multiple data sources such as Parquet, JSON, Hive and Cassandra. The Data Sources API provides a pluggable mechanism for accessing structured data through Spark SQL. Data sources can be more than just simple pipes that convert data and pull it into Spark.
Lazy Evaluation: Apache Spark delays its evaluation till it is absolutely necessary. This is one of the key factors contributing to its speed. For transformations, Spark adds them to a DAG (Directed Acyclic Graph) of computation and only when the driver requests some data, this DAG actually gets executed.
Multiple language support (Polyglot): Spark provides high-level APIs in Java, Scala, Python and R, enabling support. It provides a shell in Scala and Python. The Scala shell can be accessed through ./bin/spark-shell and Python shell through ./bin/pyspark from the installed directory.
3. Does Apache spark provide real-time processing?
Yes. Apache spark supports real-time processing through spark streaming.
4. Components of Apache Spark.
Spark Core contains the basic functionality of Spark, including components for task scheduling, memory management, fault recovery, interacting with storage systems, and more. Spark Core is also home to the API that defines resilient distributed datasets (RDDs), which are Spark's main programming abstraction. RDDs represent a collection of items distributed across many compute nodes that can be manipulated in parallel.
Spark SQL works with structured data. It allows querying data via SQL as well as the Apache Hive variant of SQLcalled the Hive Query Language (HQL) and it supports many sources of data, including Hive tables, Parquet, and JSON.
Spark Streaming is a Spark component that enables processing of live streams of data. Examples of data streams include log files generated by production web servers or queues of messages containing status updates posted by users of a web service.
Spark comes with a library containing common machine learning (ML) functionality, called MLlib. MLlib provides various machine learning algorithms, including classification, regression, clustering, and collaborative filtering, as well as supporting functions such as model evaluation and data import. It also provides some lower-level ML primitives, including a generic gradient descent optimization algorithm. All of these methods are designed to scale out across a cluster.
GraphX is a library for manipulating graphs and performing graph-parallel computations.
To achieve this while maximizing flexibility, Spark can run over a variety of cluster managers, including Hadoop YARN, Apache Mesos, and a simple cluster manager included in Spark itself called the Standalone Scheduler.
5. What is Resilient Distribution Datasets (RDD)?
Resilient Distribution Datasets (RDD), a fault-tolerant assortment of operational elements that run parallel. The partitioned data in RDD is immutable and distributed.
6. What is transformations and actions in the RDDs?
Transformations are functions executed on demand, to produce a new RDD. All transformations are followed by actions. Some examples of transformations include map, filter and reduceByKey.
Actions are the results of RDD computations or transformations. After an action is performed, the data from RDD moves back to the local machine. Some examples of actions include reduce, collect, first, and take.
7. What is the role of Spark Engine?
Spark Engine schedules, distributes and monitors the data application across the spark clusters.
8. Name the operations that Apache Spark RDD supports.
Transformation and Action.
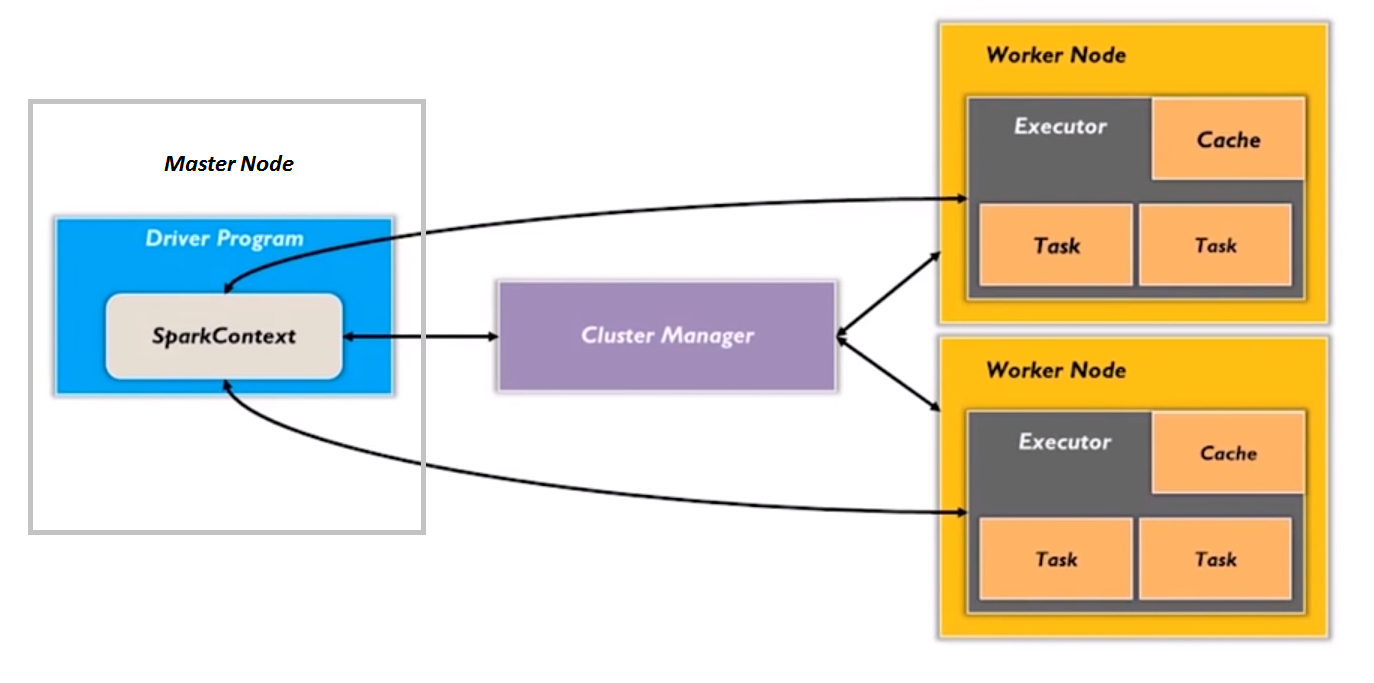
9. What is Spark Driver?
Spark Driver program runs on the master node of the machine and declares transformations and actions on data RDDs.
The driver also delivers the RDD graphs to Master, where the standalone cluster manager runs.
10. What is Spark shell?
Sparks shell provides a simple way to learn the API, as well as a powerful tool to analyze data interactively. It is available in either Scala or Python.
Scala: ./bin/spark-shell Python: ./bin/pyspark
11. What is Dataset in Apache spark?
After Spark 2.0, RDDs are replaced by Dataset, which is strongly-typed like an RDD, but with richer optimizations.
Dataset is the Sparks primary abstraction of distributed collection of items. Datasets can be created from Hadoop InputFormats (such as HDFS files) or by transforming other Datasets.
12. Explain spark streaming.
Spark Streaming is an extension of the core Spark API that enables scalable, high-throughput, fault-tolerant stream processing of live data streams. Data can be ingested from many sources like Kafka, Flume, Kinesis, or TCP sockets, and can be processed using complex algorithms expressed with high-level functions like map, reduce, join and window. Finally, processed data can be pushed out to filesystems, databases, and live dashboards.
13. Types of shared variables in Spark.
Spark supports 2 types of shared variables: broadcast variables and accumulators.
Broadcast variables allow the programmer to keep a read-only variable cached on each machine to give every node a copy of a large input dataset in an efficient manner.
Accumulators are variables that are only "added" to through an associative and commutative operation and can, therefore, be efficiently supported in parallel. They can be used to implement counters or sums.
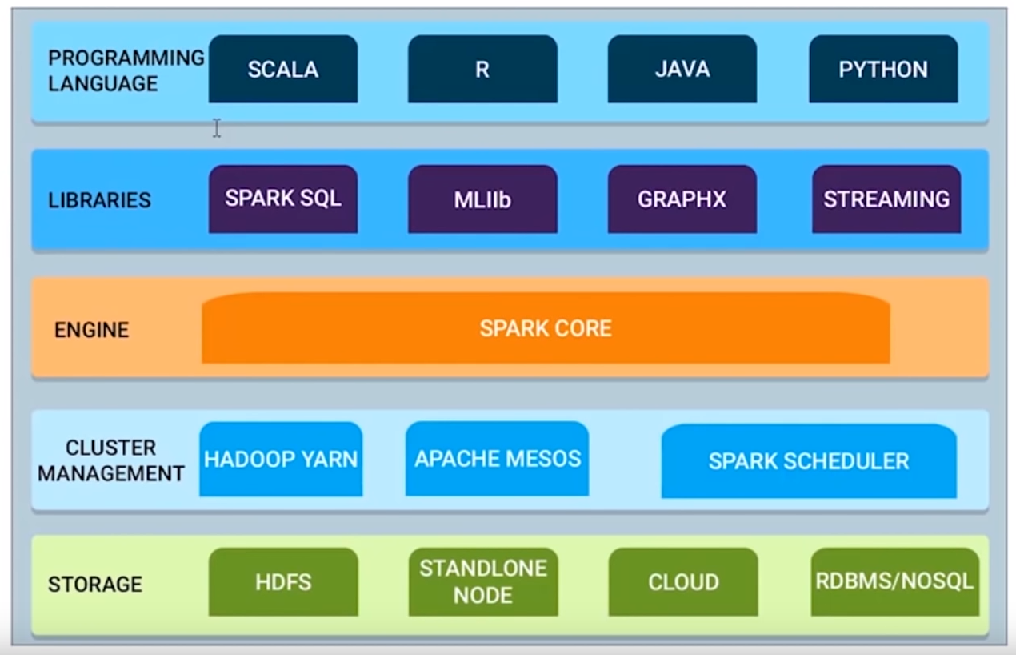
14. Spark architecture.
15. Different Spark cluster managers.
- Spark standalone cluster,
- Apache MESOS,
- Hadoop YARN,
- and kubernetes.
16. Different spark shells.
- Spark-shell with Scala support,
- PySpark with python support,
- and SparkR with R support.
17. Advantages of Spark SQL.
Spark SQL executes faster than Hive.
Hive code can be easily migrated to Spark SQL.
Spark SQL enables real time querying capabilities.
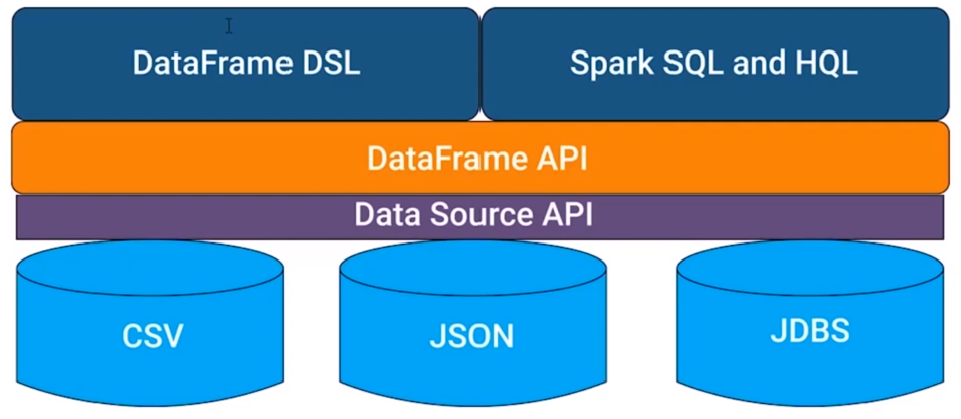
18. Spark SQL Architecture.
19. What is MLlib in Spark?
Spark MLlib is used to perform machine learning using its inbuilt algorithms and utilities.
It consists of 2 packages. spark.mllib contains the original API built on top of RDDs. spark.ml provides higher level API built on top of data frames for constructing ML pipelines. spark.ml is the primary machine learning API for spark now.
some of the popular algorithms are listed below.

20. Explain Datasets and DataFrames in Apache spark.
A Dataset is a distributed collection of data. Dataset is a new interface added in Spark 1.6 that provides the benefits of RDDs such as strong typing, ability to use powerful lambda functions. A Dataset can be constructed from JVM objects and then manipulated using functional transformations such as map, filter, etc.
A DataFrame is a Dataset organized into named columns which are conceptually equivalent to a table in a relational database. DataFrames can be constructed from a wide array of sources such as structured data files, tables in Hive, external databases, or existing RDDs.
21. Explain vectorAssembler in MLlib.
VectorAssembler is a transformer that combines a given list of columns into a single vector column.
VectorAssembler accepts the following input column types: all numeric types, boolean type, and vector type. In each row, the values of the input columns will be concatenated into a vector in the specified order.
scala> val vaDF = spark.read.option("multiLine",true).json("vectorAssemblerTest.data") vaDF: org.apache.spark.sql.DataFrame = [id: bigint, mobile: double ... 3 more fields] scala> vaDF.show +---+------+---------+----+-----------------+ | id|mobile|otherData|time| userFeatures| +---+------+---------+----+-----------------+ | 1| 1.0| yes| 18|[0.0, 11.0, 12.0]| +---+------+---------+----+----------------- scala> import org.apache.spark.ml.feature.VectorAssembler import org.apache.spark.ml.feature.VectorAssembler scala> val assembler = new VectorAssembler() assembler: org.apache.spark.ml.feature.VectorAssembler = vecAssembler_dbd3d0a8c760 scala> val assembler = new VectorAssembler().setInputCols(Array("id","mobile","time")).setOutp utCol("outputVectorColumn") assembler: org.apache.spark.ml.feature.VectorAssembler = vecAssembler_65938f964d7f scala> val output = assembler.transform(vaDF) output: org.apache.spark.sql.DataFrame = [id: bigint, mobile: double ... 4 more fields] scala> output.show +---+------+---------+----+-----------------+------------------+ | id|mobile|otherData|time| userFeatures|outputVectorColumn| +---+------+---------+----+-----------------+------------------+ | 1| 1.0| yes| 18|[0.0, 11.0, 12.0]| [1.0,1.0,18.0]| +---+------+---------+----+-----------------+------------------+ scala>
22. How do I read multiline JSON in Apache Spark?
Spark 2.2 introduced multiLine option which can be used to load JSON.
val vaDF = spark.read.option("multiLine",true).json("vectorAssemblerTest.data")
23. Difference between map and flatmap transformations.
map(func) returns a new distributed dataset formed by passing each element of the source through a function func.
flatMap(func) is similar to map, except that each input item can be mapped to 0 or more output items so that func should return a Seq rather than a single item.
